Causes and Solutions of Overfitting
Overfitting: Cause and Solution
1. Bias, Variance and Overfitting
Theoretically, we consider the expected risk of the model on real data consists of two parts:
Bias
The model's failure to imitate the real mapping, probability distribution or other relationship of the data. For example, if we try to fit a non-linear relationship with a linear model, there would be inevitable bias. Another example is that we leave some important factors omitted
Variance
The model's sensitivity to changes in data. High variance occurs when the model try to seize any details. It put too many weights on unimportant feature or noise in order to reduce error in training process.
Neither high bias nor high variance is good. However, when we take measure to solve bias, like applying complex model or increase feature, the variance of the model increase accordingly. In other worlds, there is a trade-off between bias and variance. In training process, our aim would be finding a model with bias and variance acceptable.
Underfitting and Overfitting
When the bias is high, we cannot describe the pattern of the data correctly, we call such a scene Underfitting
When the bias is low, but the variance is high, the model is trapped in the details or noises of the data, ot fit well on the given data but it has poor generality so that it would fail on other data
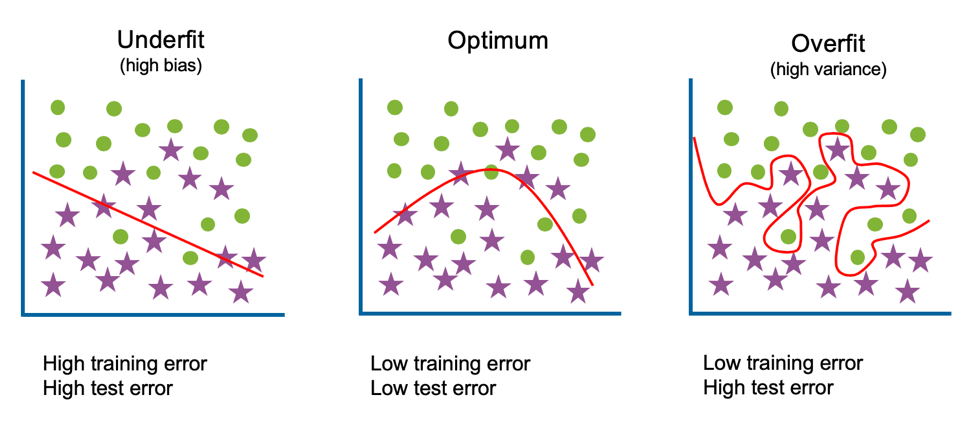
The performance on training and testing dataset under these scenes
| training SET Erro | Testing Set ERROR | |
|---|---|---|
| Underfit | high | high |
| Overfit | low | high |
| Optimum | low | low |
2. Causes of Overfitting
As specified above, the core reason that cause of overfitting is the imbalanced trade-off(High variance, low bias). Specifically, we induct the reasons into:
- Complexity of the model: The model is too complex for the pattern we want to discover in the data
- Defects of data: the samples contains so much noises that the model cannot ignore them
- Overtraining: the model is trained with too much epochs that force the model to learn noises in order to converge
- Improper sampling/splitting: the training set fails to represent the distribution of the real data. Or, in some other case, the real distribution itself decides that the model is hard to imitate it.
3. Solutions for Overfitting
According to four reasons, we can also induct the solutions into:
3.1 Control complexity
Regularization
In machine learning, regularization refer to constraints on the number of feature dimensions. Usually, it is realized through adding an regular term to the loss function to penalize putting weight on too many features. This includes:
- Lasso regression and Ridge regression
- Soft margin for SVM
- Regular term in XGBoost
- ...
Feature Engineering
Reduce the number of features. FIlter those redundant feature through feature engineering methods like correlation analysis and dimensionality reduction. For details, please refer to ongoing
Simplify Structure
An important rule for machine learning is to solve the task with possible simplest model. A model with simpler structure can usually solve overfitting. Specific action includes:
- Dropout in NN
- pruning in tree-based model
- Hyperparameter like hidden size, max-leaf-node
3.2 Data augmentation
The best way to eliminate the variance caused by data defects is simply increasing more data to the training set. Since sufficient data are sometimes unavailable in real project. We can apply data augmentation to generate more training data. Data augmentation is more common in deep learning feild.
3.3 Early stopping
Stop the optimizer earlier to prevent overtraining. For example:
- raise error threshold for an optimzer
- set max depth for an decision tree
- set max iterations for an neural network
3.4 Sampling and spliting
Cross Validation
Cross validation means spliting the dataset into subsets. Use some of them to estimate the distribution and other of them to evaluate the estimation. Such procedure can effectively control the varaince caused by sample selection bias. For the details of cross validation, refer toongoing
Sampling
From an theoretical perspective, sampling itself is actually a kind of non-parameter ML model. When you do sampling, yur actual target is to imitate the distribution of the real population through getting a sample. Thus, the sample itself would have bias if it cannot represent the true distribution of the population. Training a mode using these samples would obviously cause variance.
Thus, a way might help solving overfitting is improving your sampling method. For details of sampling methods in ML, refer to ongoing