Scaler in Machine Learning
Scaler in Machine Learning
1. About Scaling
When adopting multiple variables, many models would be effected by the difference of scales of variables. For example, distance-based clustering would enlarge the impact of variables with larger scale. Another example is that Gradient D Descending is harder to converge on unscaled data. Data Scaling can significantly improve the performance and efficiency of some models, while on other models, like tree model or Naive Bayes, data scaling does not make an influence.
2. Scaler
Scaler is those algorithm used to scaling data. They usually do not change the type of the data distribution. Four types of sclaer are listed as follows:
2.1 Standard Scaler
The Standard Scaler does the following transformation \[ x' = \frac{x-\bar{x}}{s} \] where
\(\bar{x}\) is the average of the original data
s is the standard deviation of the original data
x' is the Z-score of thr original data.
The Standarad Scaler has following properties:
The original data should fit a normal distribution. This is not a necessary hypothesis but the scaler works better if the original data has strong normality. After the transformation, the data follows N(0,1)
If the original data is not normally distributed, the standard sclater will not change it's type of distribution. In such case, consider distribution transformation methods before applying standard scaler.
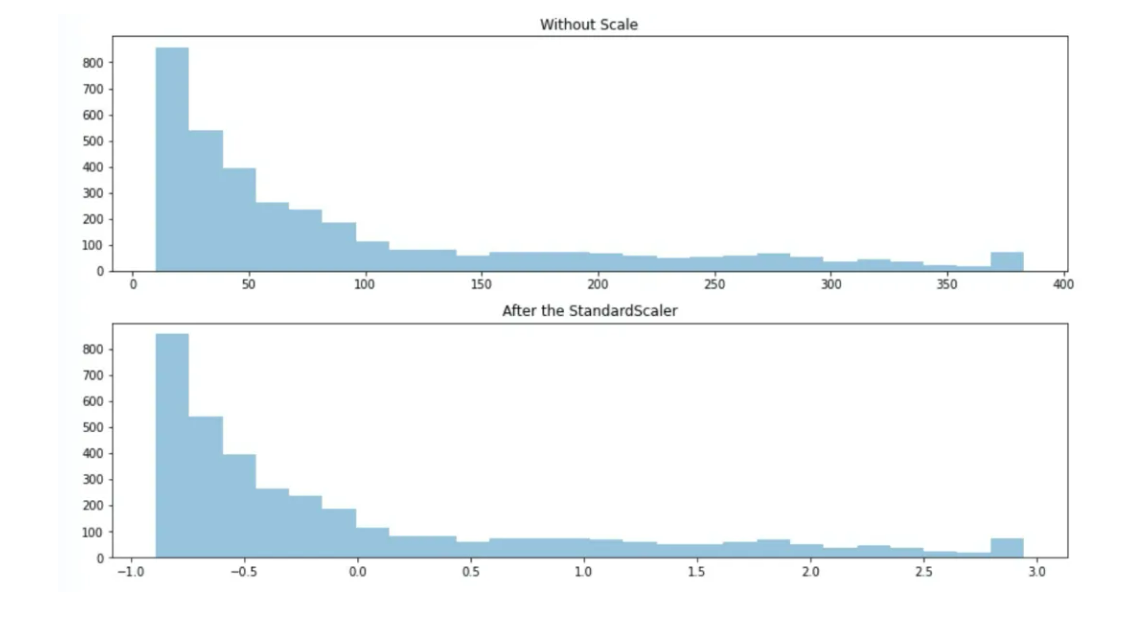
The range of transformed data is not for fixed. But most data points should lie in [-3,3].
The Outlier has an significant influence on the scaling. Consider applying outlier detection method before scaling
2.2 MinMax Scaler/Mean Normalization
The MinMax Scaler does the following transformation \[ x' = \frac{x-x_{min}}{x_{max}-x_{min}} \] The MinMax Scaler has following properties:
- The MinMax scaler is a linear transformation, it does not change the type of distribution, and it does not have hypothesis on data distribution
- The range of data after transformation would be [0,1]
- The Outlier has an significant influence on the scaling. Consider applying outlier detection method before scaling
A variant of MinMax Scaler is the Mean Normalization, which is given as: \[ x' = \frac{x-\bar{x}}{x_{max}-x_{min}} \] The Mean Normalization has similar properties as MinMax Scaler, but the range of transformed data would be [-1,1]
2.3 Robust Scaler
The Robust Scaler does the following transformation \[ x' = \frac{x-x_{median}}{IQR} \] where IQR is the difference of 75% percentile and 25% percentile
The MinMax Scaler has following properties:
- The Robust Scaler does not change the type of distribution, and it does not have hypothesis on data distribution
- The Robust Scaler reduce the influences of the outlier. If the outlier cannot be eliminated due to some reasons, we can consider this scaling method
- The range of the transformed data is not fixed
2.4 L1/L2 Scaler
The L1/L2 Scaler does the following transformation \[ x_i' = \frac{x_i}{|x|} \]
\[ x_i' = \frac{x_i }{||x ||} \] where
- x is a feature vector: {\(x_1,x_ 2,...x_ n\)}
- \(|x|,||x||\) is the L1, L2 norm of the feature vector
The L1/L2 Scaler has following properties:
- The L /L2 Scaler is a sample-level transomation, it can be applied on a single sample
- The range of the transformed data is [-1,1]
- The parameters of the distribution of the transformed data is hard to predict, since the calculated norm of each sample is different